⚡ TL;DR: An Artificial Neural Network is a computer system loosely inspired by the human brain. It is built from layers of tiny, connected units called neurons. Each neuron receives a signal, decides how important it is, and passes it forward. Stack enough layers, train it on enough data, and it can recognise your face, understand your voice, and write better than most humans.
Category: Foundational Concepts · Difficulty: Beginner · Last updated: 15 May 2026 · 6 min read
What is an ANN?
Your brain right now is reading this sentence. Billions of tiny cells called neurons are firing signals to each other. One neuron recognises a shape. It tells another. That one recognises a letter. It tells another. That one recognises a word. Eventually, your whole brain assembles the sentence into meaning — without you consciously doing anything.
An artificial neural network tries to copy that idea — not the biology, just the structure.
Instead of biological cells, it uses mathematical units called nodes (also called artificial neurons). Instead of chemical signals, it uses numbers. Instead of years of lived experience, it learns from labelled data in hours.
The result is a system that, when built big enough and trained on enough examples, can do things that once seemed like magic: recognise a face in a crowd, understand a sentence in any language, generate a photorealistic image from a text description, or predict a tumour from an X-ray.
Every impressive AI you have heard of — ChatGPT, DALL-E, Gemini, AlphaFold, your phone’s face unlock — runs on a neural network.
The 3 layers
Imagine a factory with three rooms.
Room 1 — The input layer (the door)
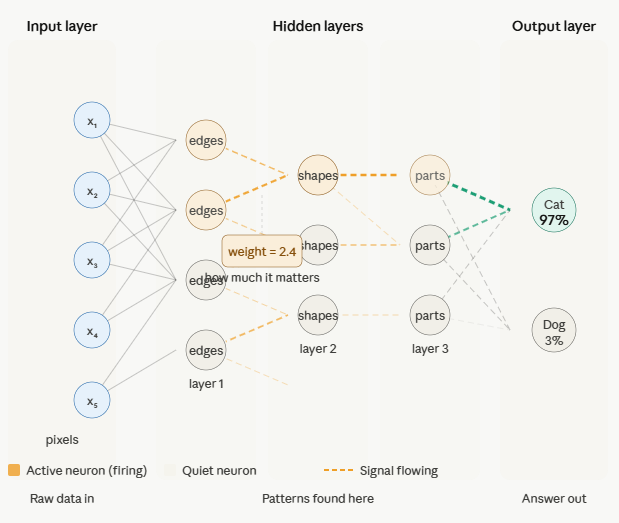
Raw information walks in here. If you are recognising a photo of a cat, the input layer receives every pixel of that image as a number — the brightness and colour of each dot. Nothing is understood yet. It is just raw data arriving at the door.
Room 2 — The hidden layers (the workers)
This is where all the thinking happens. Rows of workers (neurons) sit in layers. The first row looks at the raw pixels and finds edges — dark lines, light lines. They pass their findings to the next row. That row finds shapes — curves, triangles, pointed things. They pass it on. The next row finds parts — an ear shape, a round face, whiskers. Each row builds on what the previous row found, going from simple to complex.
A shallow network has one or two rows of workers. A deep network has dozens. That is all “deep learning” means — many hidden layers, many rows of workers building up increasingly complex understanding.
Room 3 — The output layer (the answer)
The last room assembles everything and gives you the answer. “This is a cat. 97% confidence.” Or in a language model: “The next word is probably ‘the’.”
Every neural network, no matter how complex, follows this same three-room structure. More rooms and more workers in the middle — that is the only real difference between a simple network and GPT-4.
What is a neuron actually doing?
Each neuron does three things, and only three things:
- Receives signals from the neurons before it — these arrive as numbers.
- Weighs each signal — some signals matter more than others. The weight is a number that says how much to trust each incoming signal.
- Decides whether to pass the signal forward — if the total weighted signal is strong enough, the neuron fires and sends a signal to the next layer. If not, it stays quiet.
Think of a neuron as a tiny voting booth. Many people (incoming signals) cast votes. Some votes count more than others (weights). If the total vote crosses a threshold, the decision is “yes, pass it on.” If not, “no, stay quiet.”
A single neuron is useless. Millions of neurons, organised in layers, trained together — that is where the intelligence emerges.
The process of training adjusts the weights. At the start, every weight is random — the network gives nonsense answers. Then you show it a million labelled examples (“this is a cat”, “this is not a cat”). Every time it gets an answer wrong, the weights get nudged — slightly, mathematically — in the direction of a better answer. This nudging process, repeated millions of times, is called backpropagation. Eventually the weights settle into a configuration that produces correct answers consistently.
That is the entire secret of neural networks. No magic. No understanding. Millions of tiny weights, nudged by data, until the output is right.
What is NOT a neural network ?
ANN is not a brain. It is inspired by the brain the way a plane is inspired by a bird. A plane does not flap its wings. An ANN does not use chemistry, emotions, sleep, or lived experience. It uses numbers and matrix multiplication.
ANN is not always deep learning. A neural network with one hidden layer is still an ANN but it is not deep learning. Deep learning means many hidden layers. All deep learning is ANN. Not all ANN is deep learning.
ANN is not magic or conscious. It has no awareness. It does not know what a cat is — it knows that certain pixel patterns are associated with the label “cat” in its training data. Remove the training data and it knows nothing.
ANN is not always the right tool. For simple structured data — a spreadsheet of house prices — a basic ML algorithm like linear regression often outperforms a neural network and trains 1000x faster. Neural networks shine on complex unstructured data: images, audio, text, video.
ANN is not new. The first artificial neuron was described in 1943 by Warren McCulloch and Walter Pitts. The modern deep learning revolution only began in 2012 when Geoffrey Hinton’s team used a deep neural network to win an image recognition competition by a margin that shocked the field. The idea was 70 years old. The computing power and data to make it work took that long to arrive.
Real-world examples
Real-world examples you already use
- Face unlock on your phone — a convolutional neural network maps 30,000 infrared dots on your face to a unique pattern and compares it to stored data in milliseconds.
- Spam filter in your email — a neural network reads the text of every incoming email and decides whether it looks like spam based on patterns learned from millions of labelled examples.
- ChatGPT answering your question — a massive neural network with billions of neurons arranged in hundreds of layers predicts the most likely next word, one token at a time, until a full answer is assembled.
- Netflix recommending a show — a neural network trained on viewing histories of 260 million subscribers finds patterns connecting your taste to shows you haven’t seen yet.
- Google Translate — a neural network reads a sentence in one language and generates the equivalent sentence in another, having learned the mapping from billions of translated documents.
- AlphaFold predicting protein structure — a neural network looked at millions of known protein structures and learned the rules that connect a protein’s genetic sequence to its 3D shape — solving a 50-year-old biology problem in 2020.
Types of ANN
The main types of neural network
- Feedforward ANN — the basic kind. Information flows in one direction: input → hidden → output. Used for classification and prediction.
- CNN (Convolutional Neural Network) — specialised for images. Uses a scanning technique to detect patterns regardless of where they appear in the image. Powers face recognition, medical imaging, self-driving cars.
- RNN (Recurrent Neural Network) — specialised for sequences. Has a “memory” of previous inputs. Used for time series, early language models, speech recognition.
- Transformer — the architecture behind ChatGPT, Gemini, and Claude. Uses “attention” to weigh the importance of every word relative to every other word in a sequence. Replaced RNNs as the dominant language model architecture after 2017.
- GAN (Generative Adversarial Network) — two networks competing: one creates fake data, one tries to detect fakes. The competition drives both to improve. Powers deepfakes, image generation, data augmentation.
- Autoencoder — compresses data into a small representation and then reconstructs it. Used for anomaly detection, image compression, feature learning.
Common pitfalls
Common pitfalls when working with ANNs
Overfitting — the network memorises the training data instead of learning general patterns. It aces training examples but fails on anything new. Fix: more data, dropout layers, early stopping.
Data hunger — neural networks need large amounts of labelled data. With less than a few thousand examples, a simpler ML algorithm almost always wins.
Black box problem — you cannot easily explain why a neural network made a decision. For medical diagnosis or loan approvals, this is a serious legal and ethical challenge. Explainable AI (XAI) is an entire research field tackling this.
Computational cost — training a large neural network requires hundreds of GPUs running for days or weeks. Inference (using a trained model) is cheaper but still significant at scale.
Garbage in, garbage out — a neural network trained on biased data will produce biased results. The network does not know right from wrong. It only knows the patterns in its training data.
Related concepts
- Deep Learning — neural networks with many hidden layers; the modern form of ANN.
- Algorithm — the broader concept; neural networks are a type of learning algorithm.
- Machine Learning — the field ANN belongs to.
- Transformer — the specific ANN architecture behind today’s most powerful AI.
- Training — the process of adjusting weights in a neural network using labelled data.
- Backpropagation — the mathematical technique used to adjust weights during training.
- Overfitting — when a neural network memorises training data instead of learning general rules.
- GPU — the hardware that makes training large neural networks feasible.
Frequently asked questions
QUESTION 1 What is an artificial neural network in simple terms?
ANSWER 1 An artificial neural network is a computer system inspired by the human brain. It is made of layers of small connected units called neurons. Each neuron receives information, decides how important it is, and passes it forward. Together, millions of neurons working in layers can recognise faces, understand speech, and predict the future.
QUESTION 2 What is the difference between a neural network and the human brain?
ANSWER 2 The human brain has around 86 billion neurons built from biology, powered by chemistry, shaped by decades of experience. An artificial neural network has mathematical nodes running on silicon, trained in hours or days on labelled data. The brain is the inspiration — not the blueprint.
QUESTION 3 What are the three layers of a neural network?
ANSWER 3 Every neural network has an input layer (where raw data enters), one or more hidden layers (where the network finds patterns), and an output layer (where the answer comes out). Deep learning simply means having many hidden layers.
QUESTION 4 What is a weight in a neural network?
ANSWER 4 A weight is a number that controls how much one neuron influences the next. Training a neural network means adjusting millions of these weights — over and over — until the network produces the right answer consistently.
Sources & further reading
- McCulloch & Pitts (1943). A Logical Calculus of Ideas Immanent in Nervous Activity — the paper that started it all.
- Rosenblatt, F. (1958). The Perceptron — first working artificial neuron implementation.
- LeCun, Bengio & Hinton (2015). Deep Learning — Nature — landmark paper; Hinton won the Nobel Prize for this work.
- IBM: What is a Neural Network? — ibm.com/think/topics/neural-networks
- AWS: What is a Neural Network? — aws.amazon.com/what-is/neural-network
📬 Get one concept + one use case every Tuesday. Join the newsletter →